如何制作发表质量的Venn(维恩)图
--在Venn(维恩)图中根据数据比例调整集合的大小
通过不同方法,对于不同的研究对象,你可能得到不同的列表。比如不同表达模式的基因,不同矿物的组分,以及不同特征的人群......接下来,你可能希望把它们用集合的形式显示出来,看看各部分的交集,以及哪些类别较多。最简单的方法是用PPT画出不同的圈圈,然后标上数字。如果想让不同交集的尺寸随着数字的大小而调整,可能需要花上一点功夫。 这里有一个一劳永逸的方法(Vennerable package),轻松获得和高水平文章上类似的Venn(维恩)图。
简单搜索了一下,网上还没有中文的相关文档,或者一些文档对R语言有一定的要求。于是,写了一段代码,让会用Excel、 知道R(https://www.r-project.org/)尚没有学习写R代码的同学可以做出相同的图片。把代码贴出来,让需要的同学少走些弯路。
0. For advanced R User:
Reference to Vennerable package
https://r-forge.r-project.org/projects/vennerable/
1. For R Beginner:
A. 工具安装
1)安装R环境(选最新版本下载,双击,一直按确定即可)。运行R,打开命令窗口。
2)安装Vennerable包
先下载ZIP(Windows)文件,然后Packages-->Install from Zip files
地址:https://r-forge.r-project.org/projects/vennerable/
3)导入Vennerable包
library(Vennerable)
这时R可能通知还需要其它软件包,记下需要的软件,选最新版本下载ZIP文件,并安装,或者在命令窗口输入 install.packages("XYZ"),选择服务器,确定。报错?那就先下载再安装。
B. 开始工作
1)准备数据
建立一个Excel表格,包含元素和组别的关系,“是”则大于0,“否”则为0。

这是各位同学去过的不同城市。另存为Tab 分隔的 txt 文件,取个名字比如 travel.txt。
注意,演示数据中,最好各种情况都有,数据较少并且分布奇怪,Vennerable可能会不接受。
2)开始作图(依次把命令拷贝到命令窗口)
folder<-"D:\data\tongxue"
file<-"travel.txt"
# 告诉R, 文件在哪里,叫什么名字,注意是 “\”
setwd(folder)
read.table(file,header=TRUE,sep="t",row.names=1)->venndata;
library(Vennerable)
#数据整理
probe<-rownames(venndata)
sample<-colnames(venndata)
data<-as.list(venndata)
names(data)<-sample
for (num in 1
hit<-venndata[[num]]
out<-probe[hit>0]
data[[num]]<-out
}
#数据统计
Vstem <- Venn(data)
Vstem
#数据统计好了
#根据实际,选择作图命令
# 2或3 分组
plot(Vstem)
# 4 个分组
plot(Vstem,type="ellipses",doWeights =FALSE)
# 5个及以上分组
请参照Vennerable package说明文档
# 1个分组
打开Windows PowerPoint,插入圈图即可。
当然可以把命令先拷到记事本中,编辑好后,一次拷入命令窗口。
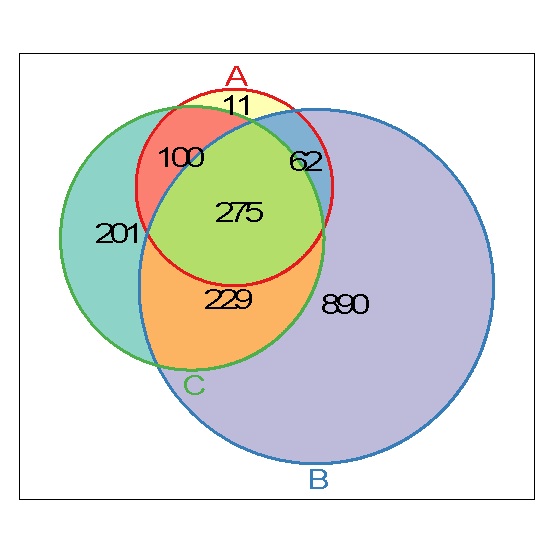
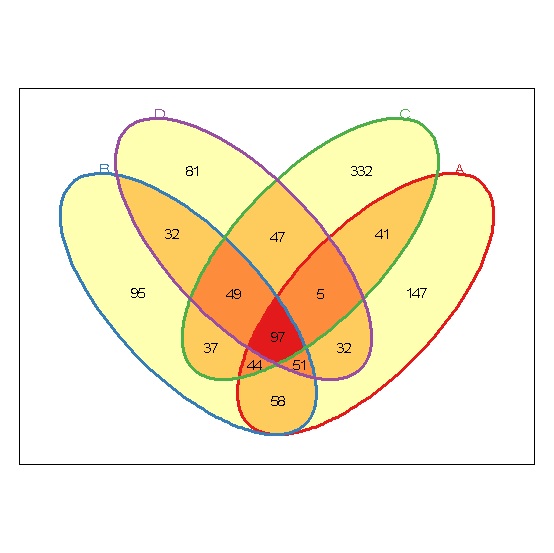
恩,是不是你想要的。接下来,右键拷贝出即可。
-------------------------------------------------------------
这里有不调整集合尺寸的作图方法:
R语言
https://www.ats.ucla.edu/stat/r/faq/venn.htm
非R语言
https://research.stowers-institute.org/mcm/venn.html
如果做四组分类建议用这个(因为Vennerable也不调整尺寸)
https://bioinfogp.cnb.csic.es/tools/venny/index.html
其它问题参照Google。






