Gopala Anumanchipalli博士,持有一组示例性颅内电极,用于记录当前研究中的大脑活动。图片来源:UCSF
中风,创伤性脑损伤和神经退行性疾病如帕金森病、多发性硬化症和肌萎缩侧索硬化症(ALS或Lou Gehrig病)常常导致不可逆转的说话能力丧失。基于此,医学上也曾给出相应解决办法,就是借助辅助设备跟踪眼睛或面部肌肉运动。然而与正常的语音(每分钟100-150字)表达相比,这样辅助表达产生文本和合成语音费力且低效(每分钟最多10个字)。
是否可以更好地帮助这类语言严重障碍患者恢复流畅的沟通能力?科学家们不断地在努力。
近日,加州大学旧金山分校(UCSF)语言科学家Gopala Anumanchipalli博士和Chang实验室的生物工程研究生Josh Chartier领导开发了人工智能新系统,可以通过控制患者大脑语音中心的活动来创建其声音的合成版本。Chang对此最新成果十分兴奋,他表示,此项研究首次表明可依据个人大脑活动生成完整的口语表达,这已然是成熟的技术,临床应用指日可待。相关研究结果发表在《Nature》杂志上。

DOI: 10.1038/s41586-019-1119-1
这项研究是建立在之前一项研究的基础之上,该研究首次描述了人类大脑的语音中心是如何编排嘴唇、下巴、舌头和其他声道组件的活动,以产生流畅的语音。对此,Anumanchipalli和Chartier意识到,之前直接解码大脑活动语音的尝试可能只取得了有限的成功,因为这些大脑区域并不能直接代表语音的声学特性,而是协调运动所需的指令。
他们招募了5名正在接受癫痫治疗的志愿者,志愿者的大脑会暂时植入电极来监测大脑活动。研究人员在 5 名受试者大声说出几百个句子时,记录下参与语言生成的大脑区域的活动。由于研究小组无法同时记录志愿者的神经活动及其舌头、口腔和喉部运动。相反,他们只记录志愿者的音频,而这种记录方法使研究人员却让他们发现了新大陆。通过识别不同的特定发声神经元群体,发现声音运动的神经代码能够被模拟。
这种声音与解剖学的详细映射使科学家能够为每个参与者创建一个真实的虚拟声道,这些声道可以通过他们的大脑活动来控制。这当中包括两个“神经网络”机器学习算法:将语音中产生的大脑活动模式转换为虚拟声道运动的解码器,以及将这些声道运动转换为参与者声音的合成近似的合成器。
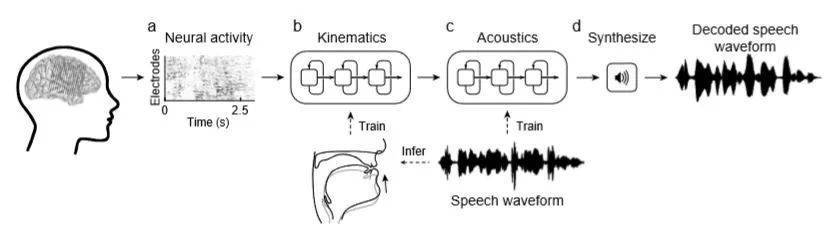
DOI: 10.1038/s41586-019-1119-1
研究人员还发现,这些算法合成的语音明显优于直接从参与者大脑活动中解码的合成语音。这些算法所产生的合成语音在进行测试时,效果十分明显。与自然语言的情况一样,抄录员能准确地识别出69%的合成词,并且能在43%的句子上完成完美精准度的转录。
目前研究人员正在试验更高密度的电极阵列和更先进的机器学习算法,他们希望这些算法能够进一步改善合成语音。该技术的下一个主要测试是确定一个不会说话的人是否能够在该系统的学习下,表达他们想说的任何内容。
“无法移动手臂和腿的人已经学会用大脑控制机器人肢体,”Chartier希望,“有一天,有语言障碍的人能够学会用这种脑控制的人工声道再次说话。”
参考文献:
[1] Speech synthesis from neural decoding of spoken sentences
[2] Syntheticspeech generated from brain recordings
[3] Study reveals brain activity patterns underlying fluent speech