人形机器人,比如这个位于东京的导购机器人,将在未来10-20年内取代许多服务业工作者。Ko Sasaki/The New York Times/Redux/eyevine
本文转载自 Nature自然科研,原文以Track how technology is transforming work为标题,发布在2017年4月13日的《自然》评论上。
技术进步为就业带来了巨大的挑战。举例来说,美国的生产力水平已经达到了前所未有的高度,但是底层50%的工作者的收入自1999年起就一直停滞不前。大部分金钱收益都进入了小部分顶层人士的手中。技术虽然不是这一现象背后的唯一原因,却有可能是最重要的原因。
4月13日,美国国家学院发布一篇报告,详细分析了信息技术对于劳动力的影响。作为报告委员会的联合主席,我们从中了解到了大量信息——包括在未来10-20年内,技术将会影响几乎每一个行业。举例来说,自动驾驶车辆可能会导致出租车和长途卡车司机的需求量减少,而在线教育或许会丰富下岗职工的再培训选择。
最重要的是,我们发现政策制定者对所谓的第四次工业革命,或者说第二次机器时代还十分茫然。在一些基础问题上,可用的数据明显缺乏,这些问题包括:以AI为代表的关键技术范围有多广,发展速度如何?哪些技术正在消灭、扩大或变革何种类型的工作岗位?哪些新的工作机会正在浮现?哪些政策选项可以在此背景下创造就业机会?
在最好的情况下,这种信息不足也会导致机会错失。往坏的方面说,它可能会带来灾难性的后果。如果我们想要了解、迎接技术进步的未知影响,并对其加以引导的话,就必须从根本上变革我们观察和追踪这些变化,以及它们的驱动因素的能力。
幸运的是,许多构建合适的数据基础架构所需的元素已经就位。人们对经济的数字认知不断增加,并且拥有了前所未有的精度、细节和及时性。私营行业也在愈发采用不同的方法来生成数据,并将其用于决策中,比如利用A/B测试来比较两种选择。与此同时,既能保护隐私,又允许共享大量数据的统计概要的技术也日益增加。
我们呼吁,制定一体化的信息策略,将公共和私有数据整合在一起,从而帮助政策制定者和公众应对技术对劳动者不断演变、且难以预知的影响。在此基础上,我们呼吁政策制定者效仿私营领域,采用循证的“感知-应对”策略。
我们所呼吁的变革是巨大的,但对就业者和经济整体来说,这些领域都是利益攸关的。
数据缺口
目前,发现、理解和应对劳动力挑战所需的许多数据并没有得到系统的收集,或者根本不存在。在我们身处的信息时代,虽然有海量的在线数据,但是政策制定者却往往缺少及时、有意义的信息,这可谓是当代的一大讽刺之处。
举例来说,虽然数字技术支持着许多消费者服务,但由于没有询问恰当的问题,美国政府的标准数据源(比如美国劳工统计局的人口现状调查)却无法准确捕捉到应急工或临时工的增加情况。研究者和私营领域的经济学家试图通过自行开展调查来解决这一问题,但这些调查缺乏政府调查的规模、范围和可信度。政府的行政数据(比如纳税申报表)是另一个富有潜在价值的数据源,但它们需要与政府调查数据整合起来,才能提供背景和验证信息。
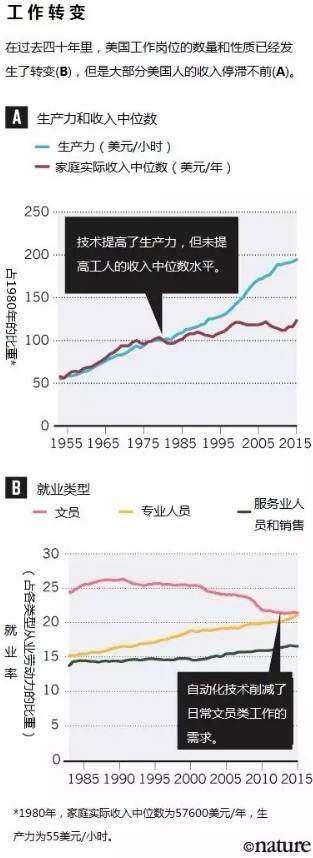
Sources: (A) https://fred.stlouisfed.org; (B) P. Restrepo https://go.nature.com/2OJCRJY (2015)
同样缺乏的还有追踪AI技术和能力进展的指标。摩尔定律(指微处理器的性能每隔两年左右就会提升一倍的规律)概括了基础半导体领域的进步,但并没有涵盖计算机视觉、语音和问题解决等领域内的快速进步。一个综合性的AI索引将能提供有关AI发展速度和广度的客观数据。
依照不同职业的技能和职责编制这样的索引将有助于教育者为未来的劳动力设计培训项目。一些非政府团体,比如斯坦福大学的人工智能百年研究(One Hundred Year Study on Artificial Intelligence)项目已经迈出了实质性步伐,但我们可以、也应该在联邦政府层面采取更多措施。
值得高兴的是,我们正处在一个数字数据的爆发期中。在逐渐意识到机器学习的力量后,各大公司已经开始捕捉各种新型数据,以优化内部流程,改善与客户和供应商之间的互动。大部分大公司已经使用了软件和数据基础架构来标准化、(在许多情况下)自动化其业务——从管理库存和订单,到处理员工休假都包括在内。
亚马逊和Netflix等互联网公司常规性地捕捉海量数据,以决定接下来向消费者推广哪些产品,提升销售额和满意度。对政府来说,这些收集实时数据的经验以及数据本身也是有价值的。
比如说,求职网站拥有数百万有关职位、职位所需技能和工作地点的数据。大学掌握着有多少学生在学习哪些课程、他们何时毕业、拥有什么技能的详细信息。机器人公司拥有消费者对不同型号的自动化装配系统的需求数据。技术平台公司拥有他们雇佣的自由职业者的数量、工作时长和地点的数据。
如果用正当的方式将这些信息相互打通,使之能为人所用,那么我们便能大大改善对目前就业状态的理解。
但在目前,不同的组织之间基本不共享任何上述类型的数据,因此,我们也无法发挥其社会价值。其中的原因包括公司不愿公开可能为竞争对手所用的数据;另外,隐私、文化惯性和监管对数据分享的限制等问题也造成了障碍。
增加试验
要利用好已有的数据,需要人们转变思维方式。在过去十年里,许多企业采取的策略从“预测-规划”变为了“感知-应对”,以快速适应不断变化的环境。通过持续收集有关消费者、竞争对手、供应商以及自身运营的海量实时数据,公司已经学会了如何不断改变自己的策略、产品供应和盈利能力。自2005年以来,采用数据驱动型决策方法的制造企业数量已经增加了两倍有余,这反映出了数据对于提升盈利能力和效能的作用。
最灵活的企业会通过实时实验来测试不同的政策和产品。比如互联网公司经常使用的A/B测试:向用户提供不同的界面,衡量哪个最有效,然后采纳最成功的那一个。
我们与在线教育提供商Udacity的创始人Sebastian Thrun就这种方法进行了讨论。正是利用该方法,他们了解到,要求学员在开课前申请入学可以显著提高学员的留存率。Udacity发现的另一个反直觉的现象是,在中国,提高价格反而使整体需求增加了两倍。

一场在伦敦进行的机器人送外卖测试。John Phillips/Getty
政府可以,而且必须学习数据驱动型决策和试验的经验。面对瞬息万变、且后果难以预料的变化,政府需要掌握实时观察并快速测试应对政策的能力,以确定哪些措施能够奏效。举例来说,政府可以通过在某一地区试行多种不同的政策来决定失业职工再培训的最佳政策:先对不同政策对就业的影响进行一年的观察,然后采用能最大化再就业的政策。当局还可以持续进行实验,以适应未来的变化。
实际上,人们已经意外采用过这种试验方法。2008年,由于州政府资金意外不足,美国俄勒冈州不得不缩减预算,采用摇号方式随机选择哪些公民可以享受政府健康保险(医疗补助计划Medicaid)。这一做法提供了有关健康福利项目因果效应的宝贵信息,并表明参保医疗补助计划能增加预防性筛查(如胆固醇筛查)。人们还有许多机会在政府项目中开展更具目的性的试验。由于很多项目都是分阶段实施的,一些随机试验便能以较低的成本,甚至零成本展开。
政府的角色
数字数据不应被当成政府以更为传统的方式收集到的信息的替代品。数字数据往往会提升、而非降低政府数据的价值。一般而言,组织在流程、商品和服务数字化过程中产生的副产品——也就是所谓的“数字尾气”并不能充分捕捉或代表根本的现象。
举例来说,根据我们的分析,Java程序员在求职招聘社交平台领英(LinkedIn)的数据库中受到了充分的代表,但卡车司机却不然。并非人人都拥有智能手机,更不要说某个特定的应用了。数字支付工具、社交网络或搜索引擎的使用情况在不同人口组别中也各不相同,从其它相关变量来看也是如此。
虽然目前可用的数据数以太字节、艾字节计,但它们仍然需要经过调整和验证。而调整和验证数据最好的方式往往是借助系统调查(如全国人口普查)和政府收集的管理数据。和产业界一样,政府也应该更广泛地利用起运行过程中作为“副产品”收集到的数据,比如高速公路自动收费或税收数据。
要收集真正具有代表性的数据,人们有时需要利用法律来保障合规性和匿名性的要求;新型的公私合作模式也可能是有必要的——这包括采取一定方式,激励最适合的私人组织收集对社会意义重大、但对其自身少有直接价值的数据。这反映出的一个事实是,通常能以接近零的边际成本实现共享的信息是终极的公共物品。
举例来说,求职网站或许没什么理由公布统计数据,说明某个经济部门的哪些失业职工通过哪个再培训项目获得了技能,从而找到了哪些特定类型的新工作。即使他们的数据已经显露出了这些趋势、对新失业职工具有重要价值、而且共享它们不会产生成本,这些网站仍然不会这么做。
我们与人力资源咨询公司万宝盛华公司、领英以及就业市场分析公司Burning Glass Technologies等私人组织的领导人探讨了这一问题。他们均对这种数据共享表达了开放的态度。
展望前路
要制订理性的公共策略以应对“工作岗位革命”,需要人们清晰地纵览变革全局。为此,我们需要做到以下三点。
第一,找到收集来自不同来源(包括私人组织)的数据和统计概要的方法。
第二,需要有可信的中间方保护数据提供者的数据隐私、存取、安全性、匿名性和其它权利,并为公众提供统计摘要(正如美国人口调查局和其它统计机构目前所做的一样)。
第三,对于反映了数据来源各不相同的统计取样偏度和偏差的数据,我们需要对其进行整合,在必要时将数据正规化,并标记出残存的偏差。
这种新的信息基础架构应与追踪关键就业表现(比如就业、收益、招聘、裁员、辞职和生产率等)的现有的核心指标整合在一起,并与来自私营领域的强大数据源结合起来。这样,统计和分析便能在瞬息万变的大环境下,为解读标准的关键经济指标提供启发。
完美并非实用的先决条件——什么都比毫无准备强。投资支持持续收集、存储、共享和分析有关工作的数据的基础架构,是政府应该采取的最重要、也是最紧迫的措施之一。