
插画作者:Simon Prades
原文以Can we open the black box of AI? 为标题
发布在10月5日的《自然》新闻上
原文作者:Davide Castelvecchi
人工智能无处不在,但科学家们在信任它之前,要先明白机器是如何学习的。
Dean Pomerleau还记得自己第一次遭遇黑箱问题的经历。那是1991年,他当时开展的开创性尝试如今已是自动驾驶汽车研究中司空见惯的问题:教会电脑如何开车。
Pomerleau说,这意味着手握一辆经过特别改装的悍马军车的方向盘,在城市中行驶。当时,他是卡内基梅隆大学机器人专业的研究生。与他同行的是一台经过他编程的计算机,能通过摄像机查看路况,解读交通状况,并记下他对各种状况的应对方式。Pomerleau希望机器最终能自己执掌方向盘。
在每次行程中,Pomerleau都会先对系统做几分钟的训练,然后让机器自行驾驶。一切似乎都进展顺利——直到有一天,悍马军车在一座桥头突然偏向了一侧。他敏捷地抓住了方向盘,这才避免了一场撞车事故。
回到实验室,Pomerleau试图理解电脑在哪里出错了。“我的论文的一部分内容就是打开黑箱,搞清楚电脑在想什么,”他解释道。但该怎么做呢?他将计算机编程为“神经网络”——一种以大脑为原型的AI,且有望比常规算法更适合应对复杂的现实情况。不幸的是,神经网络和大脑一样是不透明的。神经网络并没有将学到的东西条理清晰地储存在数字记忆中,而是以一种极其难解的方式散布信息。在全面测试了他的软件对各种视觉刺激的反应后,Pomerleau才发现了问题:神经网络一直在使用长草的路沿作为道路方向的指示,所以才被桥的出现给迷惑了。
25年后,破解黑箱的困难程度呈指数上升,但重要性也大大增加。神经网络技术本身的复杂性和应用范围也经历了爆炸式增长。现在,Pomerleau在卡内基梅隆大学兼职教授机器人学,他说,比起今天的计算机上的巨型神经网络,他的系统只能算是个简陋的低配版。用海量数据训练神经网络的深度学习技术也已经投入了各种商业应用,从自动驾驶汽车到根据用户的浏览历史推荐商品的网站都能见到它的身影。

神经网络使汽车能够学习如何驾驶自己(Pascal Goetgheluck/SPL)
神经网络还有望在科研中大显身手。未来的射电天文台会使用深度学习方法寻找值得探测的信号,否则无法处理海量的信息;引力波探测器需要用它来理解和排除最最微弱的噪声源;出版商将会用它来检索和标记数以百万计的研究论文和书籍。一些研究者认为,能进行深度学习的计算机最终或许能表现出想象力和创造力。“把数据交给机器,它便会推理出自然界的法则,”任职于加州理工学院的物理学家Jean-Roch Vlimant说。
但这些进展只会让黑箱问题显得更为突出。举例来说,这些机器是怎么找到有价值的信号的?人们怎样才能确定机器是对的?人们对深度学习的信任到底应该扩展到什么程度?“在这些算法面前,我觉得我们正在丢失阵地,”哥伦比亚大学的机器人专家Hod Lipson表示。他把这一情况类比为一种外星智能生物,他们的光受体感知的不只红绿蓝三原色,还有第四种颜色;要想让人类理解他们看待世界的方式,或是让外星人向我们解释他们的方式都会是非常困难的。计算机向我们解释问题也面临着类似的困难。“在某种程度上,这就像向狗解释莎士比亚的作品一样。”
面对这样的挑战,AI研究者们采取了和Pomerleau一样的应对方式——打开黑箱,用相当于研究人脑的神经科学的研究来理解其中的网络。但研究者们得到的答案并不是让人豁然开朗的洞见,Vincenzo Innocente表示;他是欧洲核子研究中心的一位物理学家,是在粒子物理学领域应用人工智能的先锋。“作为科学家,”他说,“我对仅仅将小猫和小狗区分开来是不满意的,科学家会希望能说出区别到底在哪里。”
好的开始
历史上第一个人工神经网络出现在上世纪50年代初,几乎与有能力执行算法的计算机同时产生。人工神经网络的思路是模拟排列成不同层次的小计算单元(也就是“神经元”),与大量数字“突触”相连。底层的单元会收集外部数据,比如图像中的像素,然后将信息传递给下一层次中的单元(可能是其中一些,也可能是全部)。下一层中的单元随后会根据简单数学法则整合来自底层的输入数据,然后将结果向上传递。顶层最终会给出答案——比如判断原图到底是“猫”还是“狗”。
这类网络的优势在于它们的学习能力。有了附带正确答案的训练数据集,神经网络便能调整每层连接的强度,直到顶层的输出结果也是正确的,大大提升其表现。这一过程模拟了大脑通过强化或弱化突触学习的过程,最终得到能成功归类不在训练集中的数据的神经网络。
在上世纪90年代,神经网络的学习能力是吸引欧核中心物理学家的一大要素。他们是在科研中例行使用大规模神经网络的先行者:这些网络对重建大型强子对撞机(LHC)在粒子对撞中产生的亚原子碎片的轨迹帮助良多。
但这种学习方式也是神经网络中的信息如此分散的原因:就像人脑一样,记忆是在许多连接中编码的,而不是像常规数据库一样储存在固定的位置。“你手机号的第一位存在大脑的哪里?也许是在一堆突触当中,也许离存储号码中其他数字的地方不远,”加州大学欧文分校的机器学习研究者Pierre Baldi说。但人脑中并没有明确定义用于编码手机号的比特序列。因此,“我们虽然是这些网络的创造者,但我们对它们的理解也并不比对人脑的理解深入多少,”怀俄明大学的计算机科学家Jeff Clune表示。

Google开发的人工智能AlphaGo在围棋这项复杂的棋类游戏中击败了世界上最强的人类棋手(图片来自Nature Video)
对需要在各自学科中处理大数据的科学家来说,这使得深度学习成了一种使用时需要多加谨慎的工具。为了理解个中原因,英国牛津大学的计算机科学家Andrea Vedaldi让我们想象这样的情景:在不久的将来,人们用乳房X光片来训练深度学习神经网络,这些X光片根据拍摄的女性之后是否罹患乳腺癌区分开来。Vedaldi说,经过训练后,一位外表健康的女性的乳腺组织在机器“看来”或许已经有了患癌的迹象。“神经网络或许暗中学会了辨认标志物——人们还不知道,但能预测癌症的特征,”他说。
但是,如果机器无法解释它是怎么知道的,Vedaldi说,就会给医生和病人带来严重困扰。对女性来说,因为拥有已知会显著提升乳腺癌风险的遗传变异而选择乳房切除术已经够困难了,但如果连风险因素是什么都不知道,做这样的选择就更加困难了,即使是在给出这一建议的机器预测非常准确的情况下。
“问题在于,获得知识的是网络,而不是我们,”Michael Tyka说,他是一位就职于Google的生物物理学家兼程序员,“我们真的理解了什么东西吗?并没有——获得见解的其实是网络。”
2012年,一些研究团队开始研究这类黑箱。Geoffrey Hinton是加拿大多伦多大学的一位机器学习专家,他领导的团队参加了一场计算机视觉竞赛,他们首次表明,深度学习从含有120万张图像的数据库中分类照片的能力强于任何其他AI方法。
为了探索这一点是如何实现的,Vedaldi的团队反向运行了Hinton用于改进神经网络训练的算法。团队没有让神经网络学习正确解读图像,而是使用了事先经过训练的网络,试图重建产生这些解读的图像。这有助于研究者识别出机器表征不同特征的方式;这就好像是在询问检测癌症的神经网络:“你认为这张乳房X光片上的哪个部分是癌症风险的标志物?”
去年,Tyka和他在Google的同事将一种类似的方法用到了极致。他们的算法名为深梦(Deep Dream),这种算法始于图像(比如花朵或沙滩),然后修正图像,以增强某个顶层神经元的反应。比如说,如果神经元想把图片标记为飞鸟,经过修正的图片中便会充满鸟儿。得到的图像就像服用LSD后见到的景象,鸟儿会从人脸上、建筑中浮现出来。比起梦境,“我觉得这更像是幻觉,”Tyka说,他也是一位艺术家。发现深梦在艺术创作方面的潜力后,他们开放了算法的下载。深梦在几天内就红遍了网络。
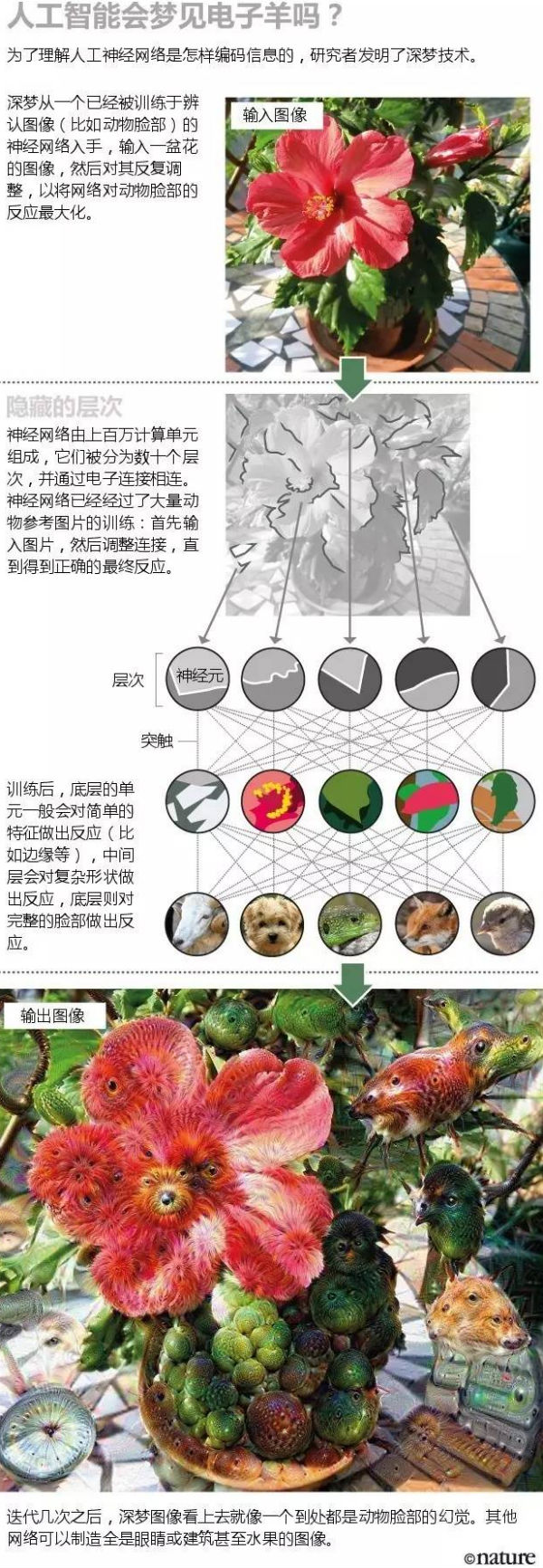
图片设计: Nik Spencer/Nature; 摄影: Keith McDuffee/flickr/CC BY; djhumster/flickr/CC BY-SA; Bernard Dupont; Linda Stanley; Phil Fiddyment/Flickr/CC BY
在2014年,Clune的团队使用了能放大所有神经元、而不仅仅是顶层神经元反应的方法,并发现黑箱问题可能比人们之前所想的更为严重:神经网络很容易被在人类看来是随机噪声的图像,或是抽象的几何图形愚弄。举例来说,神经网络可能会把曲线认成海星,或者把黑黄相间的条纹误认为校车。而且,这些图案在用别的数据集训练的网络中也造成了同样的反应。
研究者提出了一些方法来解决这个“愚弄”问题,但目前还没有找到通用的解决方法。在现实生活中,这很可能潜藏着危险。Clune说,一个尤为令人恐慌的情景是,黑客也能学会利用这些漏洞。他们可以让自动驾驶汽车认为广告牌是公路而一头撞上去,或者让视网膜扫描仪认为入侵者是奥巴马本人,把他/她放进白宫。“我们得卷起袖子做硬科学研究,让机器学习更强大、更智能,”Clune总结道。
由于这类问题的存在,一些计算机科学家认为使用神经网络的深度学习或许不是唯一有潜力的方法。英国剑桥大学的机器学习研究者Zoubin Ghahramani表示,如果要让AI提供人类能轻松理解的答案的话,“便会出现许多深度学习无法解决的问题。”2009年,Lipson和当时就职于美国康奈尔大学的计算生物学家Michael Schmidt首创了一种相对透明、且能应用于科研的方法。他们的算法名叫Eureqa;单单依靠观看简单机械物体(一组摆锤)的运动,Eureqa就重新发现了牛顿物理定律。
Eureqa从随机组合加、减、正弦和余弦等数学符号开始,使用一种受达尔文演化论启发的试错方法修正条件,直到得到描述数据的最佳公式,随后提出了检验模型的实验方法。Lipson表示,Eureqa的优势之一在于简洁。“Eureqa得出的模型一般有十几个变量,而神经网络有几百万个。”
放手去做
去年,Ghahramani发表了一种能将数据科学家的工作自动化的算法——从检查原始数据到写论文都能完成。他的软件名叫自动统计学家(Automatic Statistician),能发现数据集中的趋势和异常,呈现结论,其中还包括对推论方式的详细解释。Ghahramani说,这样的透明度对科学应用来说是“绝对至关重要”的,但对许多商业应用也很重要。比如,在许多国家中,拒绝发出贷款的银行有解释原因的法律义务——深度学习算法或许无法做到这一点。
大数据公司Arundo Analytics的数据科学主管Ellie Dobson表示,许多机构都有类似的担忧。如果调整英国利率造成了什么不好的后果,“英格兰银行总不能说,‘是黑箱让我这么干的’,”她说。
计算机科学家认为,尽管存在种种担忧,但开发透明AI应被视为深度学习方法的补充,而不是替代。他们表示,一些透明方法或许适用于已经被描述为一系列抽象事实的问题,但并不适用于感知,也就是从原始数据中提取事实。

随着摩尔定律即将走向终结,我们需要新的硬件支持更高级的计算(Rebecca Mock)
这些研究者指出,机器学习给出的复杂答案是必不可少的科学工具,因为真实世界就是非常复杂的:对天气或是股票市场这样现象来说,综合、简化的描述有可能并不存在。“有一些事情是无法用语言描述的,”巴黎综合理工学院的应用数学家Stéphane Mallat说,“如果你问医生是如何做出诊断的,医生会告诉你一些理由,”他说,“但人们为什么要用20年时间才能成为优秀的医生呢?因为信息不仅仅在书本中。”
Baldi认为,科学家应该拥抱深度学习,而不必太介意黑箱问题。毕竟,所有人的脑袋里都有一个黑箱。“人们一直在使用大脑,也始终相信大脑,但并不知道它是怎么工作的。”






